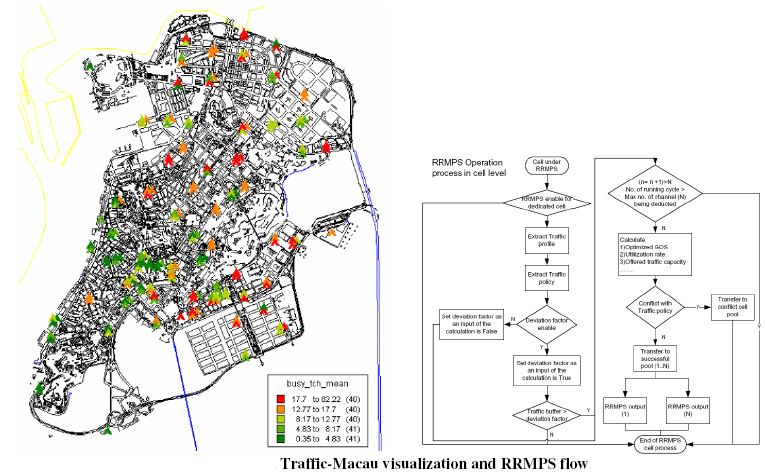
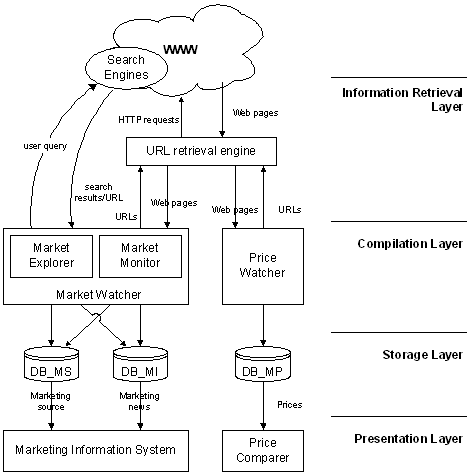
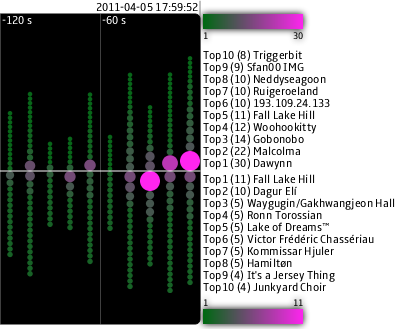
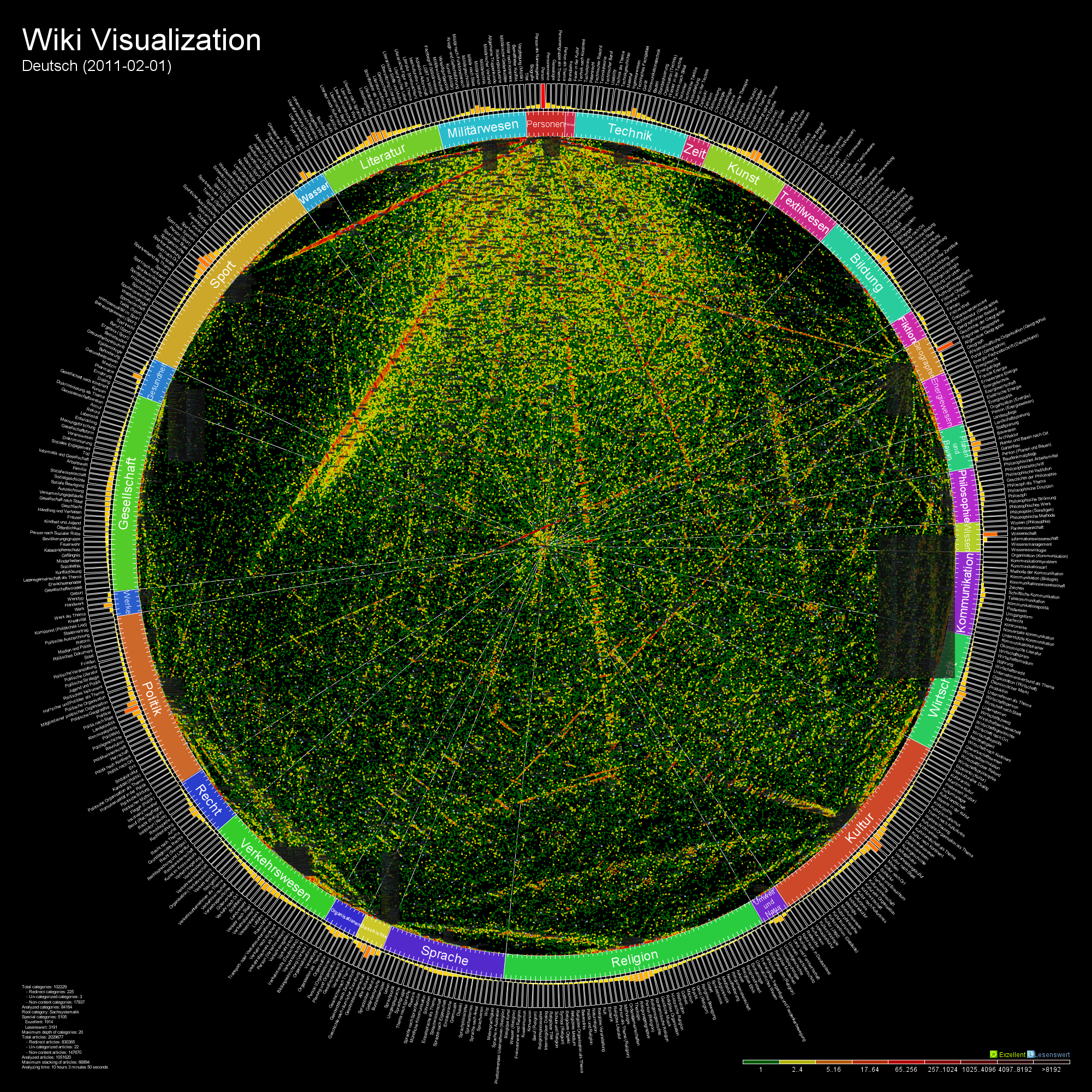
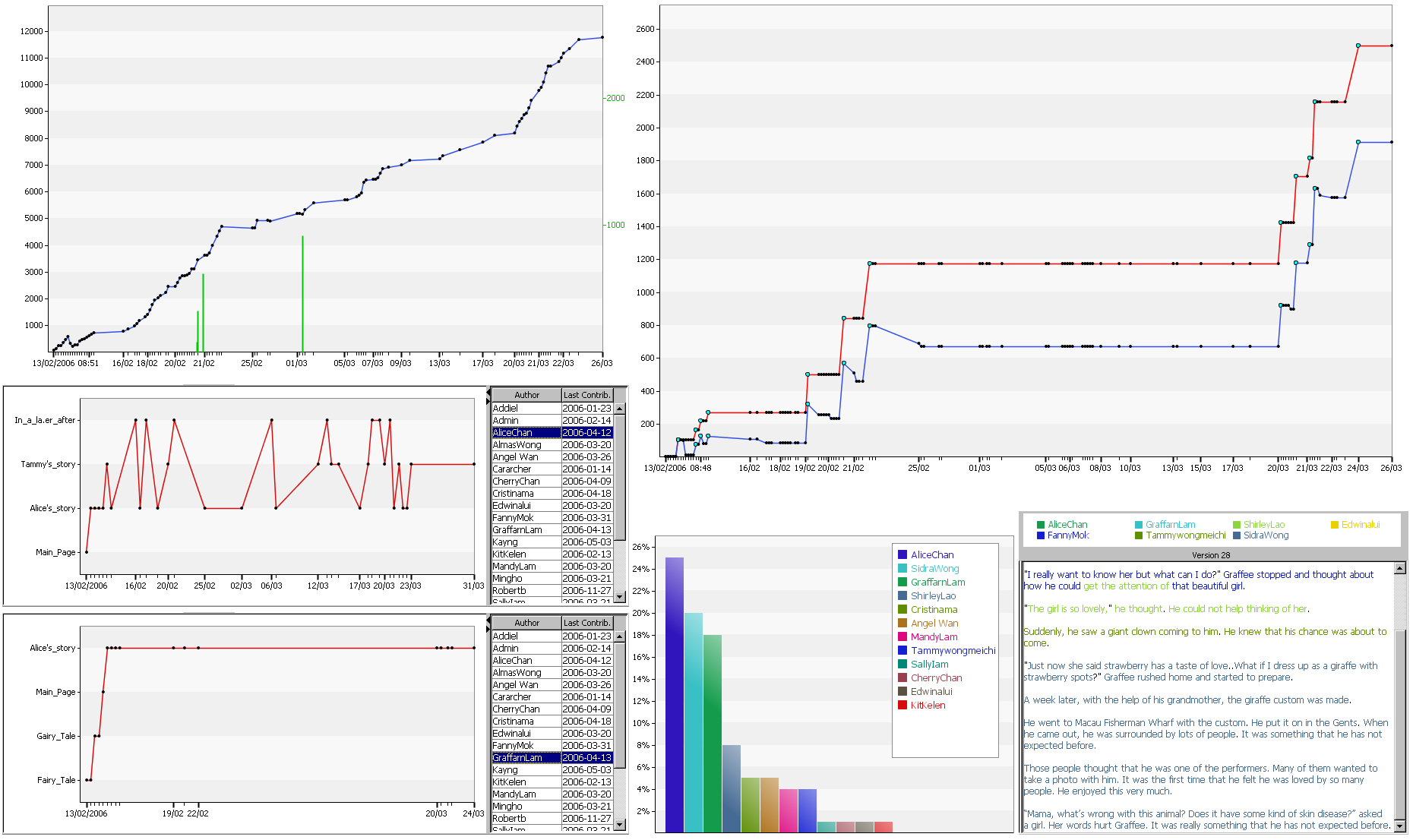
Applications
Applications
Applications
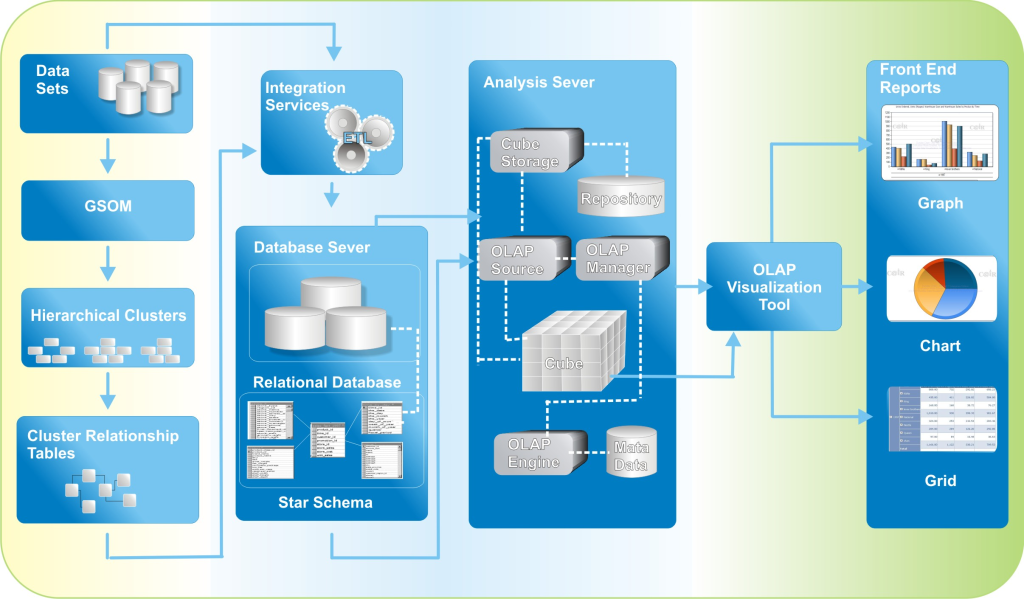
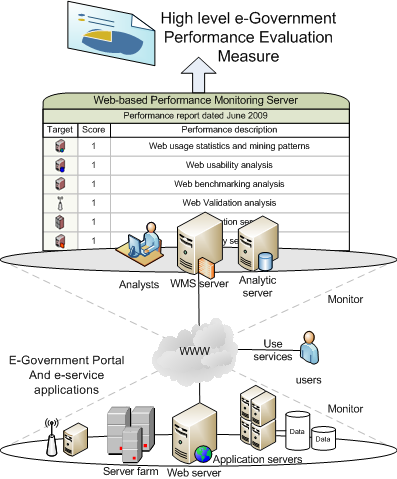
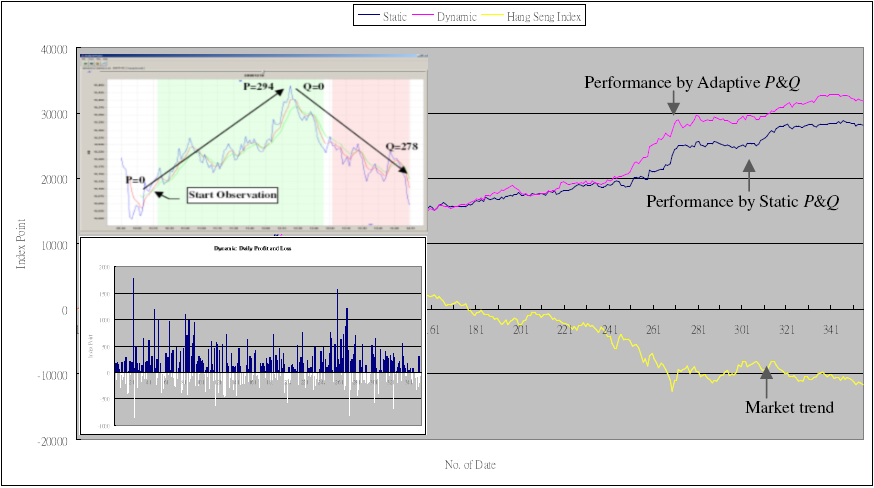
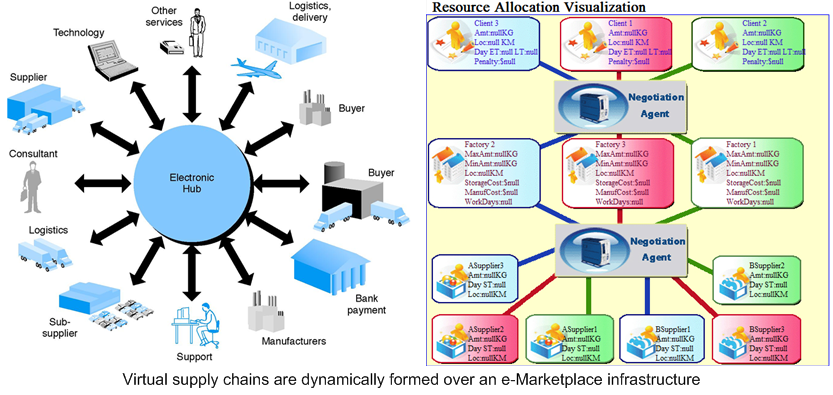
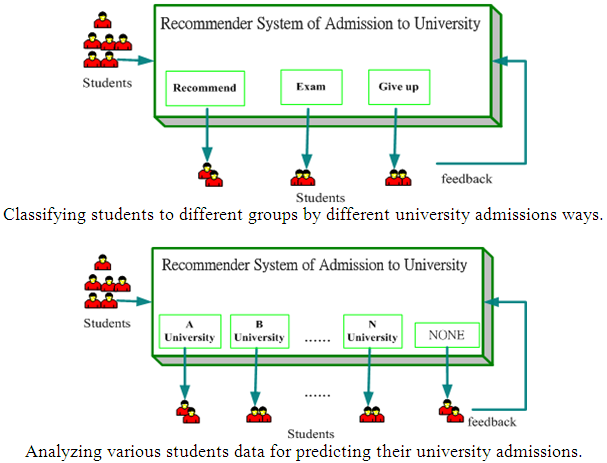
Many e-Commerce websites have widely adopted recommenders systems to automatically suggest products or services to customers for enhancing their online experiences. Amazon.com is a classical example. Recommenders assist users to narrow down their choices for making a purchase decision from a large pool of items. A simple recommendation can be generated based on the top selling products. This however assumes every customer has a common taste by a 'one-size-fits-all' approach. A more advanced approach is known as one-to-one marketing, which considers the profile of a particular user and searches for a personal match of product that is predicted to be most likely he will favour best. The technical core mechanism in e-Commerce recommenders is usually implemented in software programs by three types of filtering techniques, namely: Content-based filtering, Collaborative Filtering (CF) and Hybrid Models.
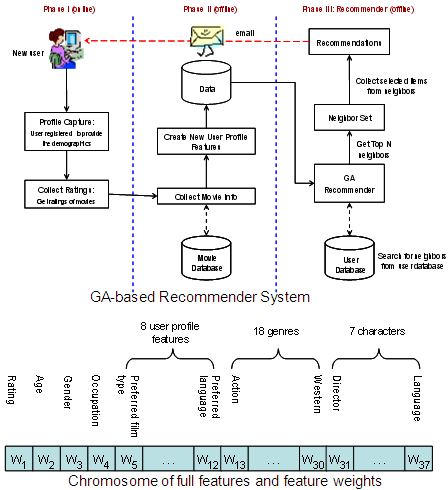
Since different types of filtering techniques have their shortcomings but advantages in certain aspects, combining them may be a promising solution provided there is a novel way of overcoming a large amount of input variables. When the filtering techniques are fused to work together, almost all the information and the relative weights about the products, users, and users' activities would be required. Genetic algorithm (GA) is an ideal optimization search function, for finding a best recommendation out of a large population of variables. Here, we present a GA-based approach for supporting hybrid modes of CF. We show how the input variables can be coded into GA chromosomes in various modes. Insights of how GA can be used in e-commerce recommenders are derived through our experiments.